How Mixture of Experts Models Are Changing AI Efficiency
Most people are looking at AI the wrong way. They think the future belongs to the biggest model, the most parameters, the fattest benchmark score, the loudest headline. That’s amateur thinking.
The real war is not just about intelligence. It’s about efficiency. Who can deliver strong answers faster, cheaper, and at scale without setting money on fire?
That’s where Mixture of Experts models hit like a hammer. They are changing AI efficiency because they stop using the whole brain for every tiny task. Instead, they wake up the right specialists at the right time. That sounds simple. It is simple. And that’s why it matters.
At Data Pips Team, we’ve tested enough AI workflows to know one ugly truth: brute force is expensive. Whether it’s ad auditing through Claude, agentic task routing, or research pipelines built on frameworks like LangChain and LangGraph, the teams that win are not the ones using more compute everywhere. They win by routing work properly.
MoE does that routing inside the model itself.
Dense models try to answer every token with the whole company. MoE wakes up only the employees who matter.
Dense Models Are Hitting a Cost Wall
Here’s the thing. Traditional dense models are powerful, but they are wasteful.
In a dense model, almost all the parameters in the active layers are used for every token. Every word, every request, every cheap little task drags a heavy compute bill behind it. That might be fine in a lab. It gets painful in production.
If you’re running millions of requests, latency matters. GPU memory matters. inference cost matters. Throughput matters. Power draw matters. Suddenly that shiny big model starts looking less like innovation and more like a bad business decision.
That’s why this topic matters far beyond researchers. If you’re building AI products, enterprise automation, or agent systems, efficiency is not a side detail. It’s the business model.
We already broke down why foundation models matter. Now take the next step. Understand that not all foundation model architectures scale the same way.
Dense Scaling Gets Ugly Fast
When you make a dense model larger, you usually get more capability. Fine. But you also increase the amount of computation needed for each forward pass. That’s the tax.
The bigger it gets, the more expensive each token becomes.
Look, if every request needs the full model, then every simple customer support question, every short summary, every lightweight classification call is paying for the whole engine. That’s waste.
| Model Style | How It Uses Parameters | Cost Per Request | Scalability Pressure |
|---|---|---|---|
| Dense Model | Most active parameters are used on every token | Higher and more predictable | Gets expensive fast as size grows |
| MoE Model | Only selected experts activate per token | Lower active compute relative to total capacity | Can scale capacity without fully scaling compute |
This is exactly why the industry started pushing harder into sparse architectures. Not because “sparse” sounds clever. Because dense-only scaling eventually punches you in the face with cost.
Mixture of Experts Models Turn One Brain Into a Specialist Team
Let’s kill the confusion.
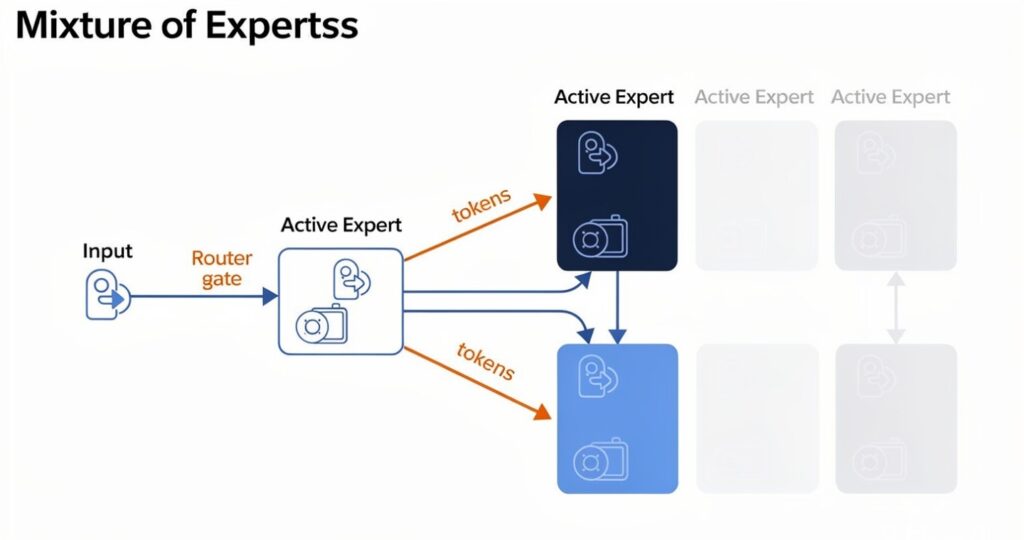
A Mixture of Experts model is basically a model architecture where different expert sub-networks exist inside the system, and a routing mechanism decides which experts should handle a given token or input.
Not all experts wake up. Only the selected ones do.
That’s the core efficiency trick.
The Right Analogy Makes This Obvious
When our founder worked as an electrician and plumber, he didn’t carry the entire workshop into every job and use every tool on every problem. That would be idiotic.
If a wire was faulty, he used the right tool for the wire. If a pipe was leaking, he used the right tool for the pipe. He didn’t drag the whole shop into one screw.
Dense models do exactly that. They drag the whole toolbox into every token.
MoE models don’t. They call the right specialist.
The Router Is the Foreman
Inside an MoE architecture, there’s usually a routing or gating mechanism. Its job is simple: look at the input and decide which experts should process it.
Sometimes it’s top-1 routing. Sometimes top-2. That means the system might choose one or two experts for each token instead of waking up every expert available.
This is why you can have a model with huge total parameter capacity while using only a fraction of that compute during inference.
Read the Hugging Face MoE guide if you want the deeper engineering explanation. But don’t miss the business meaning: more total knowledge, less active waste.
Active Parameters Matter More Than Vanity Parameters
Here’s where beginners get fooled.
They see a model with a giant parameter count and assume it’s automatically too expensive or too slow. Wrong. In MoE, total parameters and active parameters are not the same thing.
That difference matters.
| Term | What It Means | Why You Should Care |
|---|---|---|
| Total Parameters | Everything the model contains | Shows overall capacity |
| Active Parameters | The subset actually used for a token | Drives much of the real compute cost |
| Routing | The selection logic for experts | Determines efficiency and quality balance |
| Load Balancing | Keeping experts from being overused or ignored | Prevents bottlenecks and collapse |
Pro Tip: if you’re evaluating an MoE model and only looking at total parameter count, you’re already behind.
AI Efficiency Changes When Only the Right Experts Wake Up
Now we get to the money section.
Why are Mixture of Experts models changing AI efficiency so aggressively? Because they let model capacity scale faster than active computation.
That means you can push toward stronger performance without paying dense-model prices on every single token.
MoE Creates Four Major Efficiency Wins
First, lower compute per token relative to total capacity. That’s the obvious one.
Second, better specialization. Different experts can become better at different patterns, languages, domains, or reasoning styles.
Third, stronger scaling economics. You can grow capability without turning every request into a GPU bonfire.
Fourth, better product viability. If the model is cheaper to serve, more businesses can actually deploy it.
This is why MoE matters to real operators, not just AI Twitter tourists.
Training and Inference Both Feel the Impact
Don’t oversimplify this. MoE is not free magic.
Yes, active compute can be lower. But training and serving MoE models brings its own engineering headaches: routing instability, expert imbalance, communication overhead across devices, memory pressure, and batch inefficiencies.
Google’s Switch Transformers paper helped push this conversation forward by showing how sparse expert architectures could scale massively. Later, work like Expert Choice routing from Google Research kept improving how experts are assigned and balanced.
So no, MoE is not a cheat code. It’s a smarter architecture with trade-offs. Adults understand both sides.
The Industry Already Moved While Most People Were Still Arguing
While half the internet was busy worshipping model size, serious labs were fixing efficiency.
That’s the part people miss. The shift to MoE wasn’t random. It was forced by economics.
If you want strong models that can serve huge user bases, support multilingual workloads, handle coding, reasoning, and enterprise tasks, and still make business sense, you need better compute economics. Dense-only thinking starts to crack.
Case Study: Three Signals That MoE Became Serious
| Signal | Why It Mattered | Efficiency Lesson |
|---|---|---|
| Switch Transformers | Showed sparse expert scaling could reach extreme model capacity | Capacity does not need dense compute every step |
| Open-weight MoE models like Mixtral | Brought MoE discussion into mainstream developer workflows | Strong quality can arrive with selective activation |
| Deep enterprise AI adoption | Forced teams to care about cost per request and throughput | Architecture choices decide whether AI is profitable or just impressive |
Honestly, this is the same lesson we keep seeing across AI operations.
At Data Pips Team, when we tested AI-assisted ad auditing and agentic analysis workflows, one pattern was obvious: the best systems did not throw the biggest model at every subtask. They separated research, scoring, rewrite logic, and tool calls cleanly.
MoE applies that exact principle inside the model.
Not identical. But the logic is the same: specialization plus routing beats brute force plus ego.
MoE Is Not the Same as Multi-Agent Systems
Don’t mix up internal model architecture with external orchestration. That’s rookie confusion.
MoE happens inside a model. Multi-agent systems happen outside the model.
An MoE model routes tokens to expert subnetworks inside one architecture. A multi-agent system routes tasks across separate agents, tools, prompts, and workflows.
If you still need the bigger picture, read our breakdown on multi-agent systems in enterprise automation and what agentic AI actually means.
Here’s the clean way to think about it:
- MoE = internal selective compute
- Agents = external task orchestration
- Together = smarter systems end to end
This matters because people keep comparing the wrong layers of the stack. Stop doing that.
What Actually Works With MoE in Production
Let’s stop talking like academics and talk like operators.
Where do Mixture of Experts models actually shine?
They Work Best When Task Diversity Is High
If your system handles multilingual queries, code generation, reasoning, summarization, enterprise knowledge tasks, and domain-heavy requests, MoE can shine because specialization has room to matter.
One expert gets sharper on one kind of pattern. Another handles another pattern. The router does the sorting.
They Work Best When Cost Pressure Is Real
If you’re serving large user volume, efficiency is not optional. It’s oxygen.
That’s why MoE belongs in serious conversations about AI agents replacing traditional workflows. If the economics don’t hold, the workflow dies no matter how pretty the demo looked.
They Work Best With Strong Infrastructure Discipline
Good teams don’t just pick an MoE model and pray. They benchmark latency, expert balance, memory use, throughput, and quality under real request patterns.
That’s what professionals do.
They also compare MoE choices against the rest of the stack: quantization, batching, caching, retrieval, prompt compression, and orchestration frameworks. If you skip that, you’re not evaluating architecture. You’re gambling.
They Work Best When You Stop Worshipping One Metric
Benchmark score alone is not enough.
You need to care about:
- cost per million tokens
- latency under concurrency
- output quality consistency
- routing stability
- memory footprint
- serving complexity
This is the same mindset we bring when comparing tools like AutoGen vs CrewAI vs LangGraph or reviewing the top AI agent frameworks developers should know. The winner is not the one with the coolest homepage. The winner is the one that performs under pressure.
Where Most People Go Wrong With MoE
This section matters, because hype makes people stupid.
They Think MoE Automatically Means Cheap
No. It often means more efficient active compute, but deployment can still get messy. Expert routing across devices can create communication overhead. Memory demands can still be large. Poor batching can wreck your gains.
MoE can be efficient. It is not automatically cheap.
They Ignore the Router Like It Doesn’t Matter
The router is not decoration. It’s the traffic cop.
If routing is weak, experts get overloaded, underused, or collapse into bad specialization patterns. Then your shiny MoE becomes a confused expensive machine.
Read IBM’s overview of Mixture of Experts and you’ll see the same pattern: the architecture is powerful, but routing quality is central.
They Benchmark on Toy Prompts
This is a disease in AI.
Teams run ten clean prompts, get a nice result, and start acting like they’ve solved inference economics. Then real users arrive with messy inputs, uneven traffic, edge cases, multilingual noise, and longer context windows. The system bends.
Production does not care about your lab fantasy.
They Forget That Sparse Compute Still Needs Dense Thinking
You still need serious engineering discipline around monitoring, serving, fallback logic, and workload analysis. MoE is not a shortcut around competence.
They Use MoE as a Buzzword Instead of a Decision Tool
Look, if you don’t know why you’re choosing an MoE model, don’t choose it.
Use it because the workload justifies it. Use it because the economics improve. Use it because the architecture matches the product. Not because LinkedIn turned it into the week’s favorite costume.

MoE Is Reshaping AI Products, Not Just Research Papers
The biggest mistake you can make is treating MoE like an academic side quest.
It is a product architecture decision.
If you’re building customer support copilots, research tools, coding assistants, multilingual enterprise search, automated analytics, or domain agents, efficiency determines whether the business survives.
That is why MoE matters.
At Data Pips Team, we’ve seen this lesson repeatedly in AI and business experiments. The stack that wins is rarely the one with the most brute force. It is the one with the least waste.
That applies to model design, workflow design, and business design.
You can read more about that bigger shift in our piece on AI technology in 2026. The future isn’t just “more AI.” It’s more usable AI at sane economics.
Quick Action Steps
- Stop judging AI models by total parameters alone. Ask about active parameters, routing, and cost per request.
- Benchmark with real workloads. Toy prompts lie. Production traffic tells the truth.
- Compare architecture to business need. If your workload is diverse and high-volume, MoE deserves a serious look.
- Track the full efficiency stack. Measure latency, throughput, memory use, and serving complexity together.
- Separate hype from architecture. Use MoE because the economics work, not because the term sounds advanced.
- Study the stack, not just the model. Routing, orchestration, quantization, caching, and infra discipline all matter.
Frequently Asked Questions
What are Mixture of Experts models in simple terms?
Mixture of Experts models are AI models built with multiple expert subnetworks inside them. A router decides which experts should handle each token or input, so only a small subset of the model is active at once. That selective activation is the core efficiency advantage.
Why are MoE models more efficient than dense models?
Dense models use most active parameters for every token. MoE models use only selected experts for each token. That means they can offer large total capacity without fully paying the dense compute cost on every request. In plain English: less waste, better scaling economics.
Are Mixture of Experts models always cheaper to run?
No. They often reduce active compute, but they also introduce routing, memory, communication, and serving complexity. If your infrastructure is weak or your workload doesn’t benefit from specialization, the savings can shrink fast.
Do MoE models perform better than dense models?
Not automatically. Performance depends on architecture quality, routing strategy, training process, workload type, and deployment setup. In many cases, MoE can deliver strong quality with better efficiency, but there is no universal free lunch.
Are MoE models the same as multi-agent systems?
No. MoE is an internal model architecture. Multi-agent systems are external workflows that coordinate separate agents, tools, prompts, and actions. One is inside the model. The other is around the model.
Where do Mixture of Experts models work best?
They work best in high-volume, diverse workloads where specialization and efficiency both matter. That includes multilingual systems, enterprise AI, coding assistants, research tools, and complex user-facing applications that need strong quality without runaway serving cost.
What is the biggest mistake teams make with MoE?
The biggest mistake is assuming the acronym does the work for them. Teams ignore routing quality, benchmark on toy prompts, and fail to measure full production economics. Then they act surprised when deployment gets ugly.
MoE Is Not a Trend. It’s an Efficiency Weapon
Let’s finish this properly.
Mixture of Experts models are changing AI efficiency because they attack the real problem: wasted compute. They let systems scale capacity without dragging the full weight of a dense model through every tiny request.
That doesn’t mean MoE is magic. It means the people building serious AI systems now have a sharper tool. And sharp tools reward competent hands.
So stop staring at benchmark screenshots like a tourist. Start asking harder questions. What are the active parameters? How good is the routing? What does serving actually cost? Where does it break under load?
That’s how grown-ups evaluate AI.
Now do the work. Pick one model stack you’re watching, dense or sparse, and audit it properly this week. If you can’t explain its efficiency profile in plain English, you’re not ready to build with it.
Disclaimer: This article is for educational and informational purposes only. It does not constitute technical, financial, investment, or legal advice. Model capabilities, costs, and performance vary by provider, infrastructure, and workload. Always validate claims through your own benchmarking and engineering review. Any disputes arising from this content shall be governed by the Courts of Singapore.


