
- RAG answers “what does the model know” by pulling in fresh data at query time. Fine-tuning answers “how does the model behave” by changing the model itself.
- For most businesses in 2026, RAG is the faster, cheaper, lower-risk starting point — fine-tuning is the exception, not the default.
- The architecture most production systems are quietly converging on is a hybrid: a small fine-tuned model for tone and format, sitting behind a RAG pipeline for live knowledge.
- Picking the wrong architecture early does not just cost money — it can quietly drain a project’s budget for years before anyone notices the mistake.
Fine-tuning vs RAG is the single most important architecture decision in any serious AI project, and most teams get it wrong before they even realize a decision was made. Someone in a meeting asks “should we fine-tune the model or build a retrieval system around it,” everyone nods like they understand the trade-offs, and the project moves forward on a foundation nobody actually evaluated properly.
This is not a small technical detail you can fix later. The fine-tuning vs RAG decision determines your system’s cost structure, how fast you can update it, how much engineering talent you need to maintain it, and whether it can scale past a pilot into something that actually runs in production.
The Data Pips Team has spent real time inside AI agent frameworks, automation pipelines, and business AI tooling — not theory, hands-on experimentation. This article cuts through the marketing noise around both approaches and gives you a direct, practical answer to which one fits your situation in 2026.
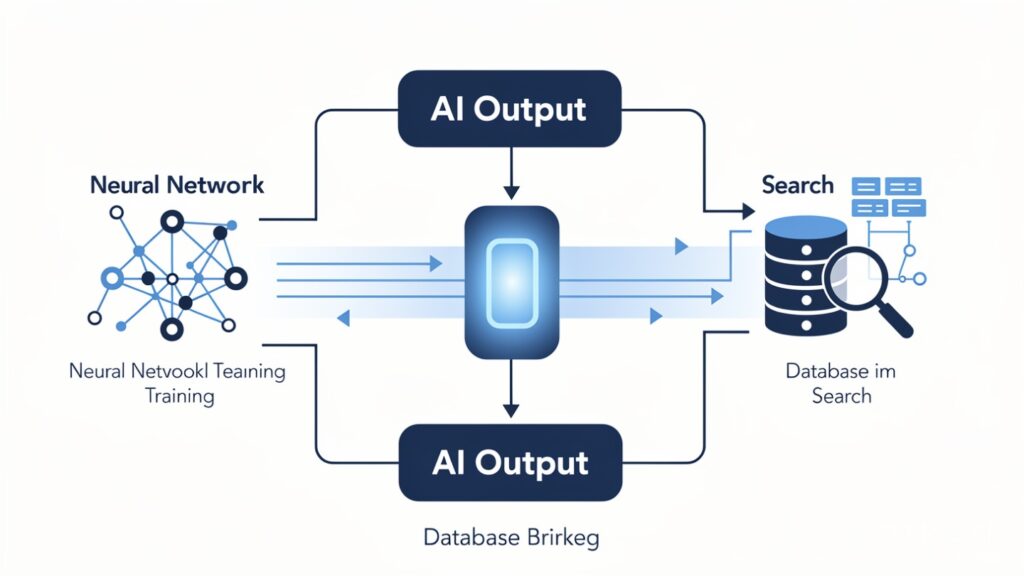
Table of Contents
Fine-Tuning vs RAG: What Each One Actually Does
Strip away the jargon and the decision comes down to one core question: do you need to change what the model knows, or do you need to change how the model behaves?
RAG (Retrieval-Augmented Generation) connects a language model to an external knowledge source at the moment a question is asked. When a user submits a query, the system searches a database of your documents, pulls back the most relevant pieces, and feeds them into the model’s prompt alongside the question. The model never gets retrained — it simply gets handed the right information right before it answers.
Fine-tuning takes a different approach entirely. It actually adjusts the internal weights of the model through additional training on a curated dataset of examples. The model is changed at a structural level — its tone, its output format, its understanding of domain-specific terminology, even its reasoning patterns on narrow tasks.
RAG solves the “what does the model know” problem. Fine-tuning solves the “how does the model behave” problem. Confusing these two purposes is exactly where most teams go wrong before the project even starts.
Why RAG Has Become the Default Starting Point in 2026
Industry data backs this up clearly. A 2025 Gartner survey found that over 70% of enterprise AI teams deploying large language models in production use RAG as their primary knowledge-grounding technique, while fewer than 25% use fine-tuning as a standalone approach.
The reason is practical, not philosophical. Most business knowledge changes constantly — pricing, policies, product specs, customer histories, support documentation. If that information is updated weekly or monthly, RAG lets you update the knowledge base directly without ever touching the model. Fine-tuning that same knowledge would require retraining every time something changes, which adds cost, delay, and risk to a process that should be simple.
For most business AI use cases in 2026, RAG is genuinely cheaper and faster to get into production. Internal documentation, legal agreements, customer support tickets, and product manuals are rarely part of any model’s original training data — RAG makes this information accessible to the model without ever exposing it during a training process.
| Factor | RAG | Fine-Tuning |
|---|---|---|
| Best for | Frequently changing knowledge | Stable behavior, tone, and format |
| Setup speed | Fast — days to weeks | Slower — needs curated dataset and training cycles |
| Update process | Update the document store directly | Requires retraining the model |
| Data requirement | Documents to index, no labeling needed | Hundreds to thousands of high-quality labeled examples |
| Cost at scale | Can rise with high query volume | Lower per-query cost at very high volume |
| Maintenance burden | Retrieval quality monitoring, document freshness | Retraining schedules, dataset maintenance |
Notice the bottom row carefully. Neither approach is maintenance-free. The real question is not “which one requires no upkeep” — it is which maintenance burden fits your team’s actual capabilities.
“RAG tells the model what to know right now. Fine-tuning tells the model who to be permanently. Most businesses need the first one far more than the second.”
— Data Pips Team
When Fine-Tuning Actually Wins
RAG being the default does not mean fine-tuning is obsolete. There are specific, well-defined situations where fine-tuning is genuinely the better choice — and pretending otherwise just to avoid the complexity of training a model is its own mistake.
Your domain language is stable. If you operate in a specialized legal sub-practice, a clinical specialty, or a fixed product taxonomy that does not change month to month, the knowledge volatility problem RAG solves simply does not apply to you as strongly.
You need consistent format or tone that prompting cannot reliably enforce. RAG is excellent at injecting facts. It is not as reliable at forcing a model to always respond in a specific structured format, always follow a particular voice, or always call a specific tool in a specific sequence. This is a behavioral requirement, and behavior is fine-tuning’s strength.
You are running extremely high query volume on a narrow task. If you are making millions of API calls a day on a tightly scoped task — like classification or structured data extraction — a smaller, fine-tuned model can be meaningfully cheaper per call than a large general-purpose model paired with a RAG pipeline, because the upfront training cost gets amortized across enormous volume.
You have the data to support it. Fine-tuning genuinely requires hundreds to thousands of high-quality labeled examples, plus compute resources for training and a process for properly evaluating whether the fine-tuned model actually beats the base model. Without this data foundation, fine-tuning becomes guesswork.
The Hybrid Pattern Most Production Systems Are Quietly Adopting
Here is what most surface-level comparisons of fine-tuning vs RAG completely miss: the most capable production AI systems in 2026 are not choosing one over the other. They are combining both, with each one solving a different half of the same problem.
The pattern that has become standard practice across serious AI deployments: fine-tune a smaller, efficient open model specifically for behavior, output format, and domain vocabulary — then put that fine-tuned model behind a RAG pipeline that handles live, current knowledge retrieval. The fine-tuning controls how the model sounds and structures its answers. The RAG layer controls what facts it has access to right now.
This hybrid approach gives you fast inference, a strong, consistent domain voice, and citable, current answers grounded in real data — without forcing a single architecture to do a job it was never well suited for. It is more complex and more expensive to build than either approach alone, which is exactly why it is reserved for situations where both behavioral precision and knowledge breadth genuinely matter at scale.
This mirrors a principle the Data Pips Team applies across business strategy generally: do not force one tool to solve two unrelated problems. Distribution and product are different problems. Knowledge and behavior are different problems too. Our breakdown of foundation models and why they matter goes deeper into the underlying model architecture that both RAG and fine-tuning sit on top of.
While experimenting with AI agent frameworks including LangChain, CrewAI, AutoGen, and LangGraph, an early approach attempted to bake too much specific, frequently-changing business knowledge directly into a model’s behavior layer rather than separating it into a retrievable knowledge store. The result was a system that needed constant rebuilding every time the underlying information changed — exactly the trap teams fall into when they pick fine-tuning for a knowledge problem instead of a behavior problem. Separating “what the system knows” from “how the system behaves” into two distinct layers solved the problem far more cleanly than continuing to patch a single, overloaded approach.
How to Actually Decide: A Practical Framework
Skip the theoretical debate. Ask yourself these direct questions in order.
Does the AI need access to data that changes weekly or more often? If yes, RAG is close to mandatory. Fine-tuning that information would mean retraining on a schedule no team wants to maintain.
Do you need source citations for compliance or trust? RAG naturally supports this because it can point directly back to the retrieved document a fact came from. Fine-tuned models cannot easily cite where a piece of knowledge came from, since it is baked into the weights rather than retrieved from a traceable source.
Do you have the ML engineering resources for ongoing model management? If your team does not have dedicated machine learning engineering capacity, RAG is the pragmatic choice. Fine-tuning without proper evaluation infrastructure produces models nobody can confidently trust or maintain.
Is your use case narrow, high-volume, and behaviorally specific? If you are running a tightly scoped task at massive scale where consistent format matters more than fresh knowledge, fine-tuning may genuinely reduce your per-call costs over time.
For most enterprises in 2026, the practical answer is to start with RAG, get to a working production system fast, and evaluate fine-tuning only once you hit a specific behavioral requirement that RAG genuinely cannot solve on its own.
What Nobody Tells You About Fine-Tuning vs RAG
1. Neither approach is “set it and forget it.” Marketing content around both options tends to imply you build it once and walk away. In reality, RAG systems require continuous monitoring of document freshness, query drift, and retrieval relevance. Fine-tuned models require retraining schedules and ongoing evaluation. Pick the maintenance burden you can actually sustain, not the one that sounds easier in a sales pitch.
2. Vendor lock-in is a real, underestimated risk with RAG. Some RAG pipelines create hard dependencies on specific vector database vendors or embedding API providers that become genuinely expensive to undo later. Fine-tuned models tend to be more portable across hosting environments. Evaluate this before committing to a stack, not after you are three months into production.
3. Architecture decisions made too early are quietly killing AI pilots. Less than 30% of enterprise AI pilots actually scale to full production deployment, and a significant reason cited consistently is architecture decisions locked in before the team understood the actual trade-offs. The meeting where someone casually decides “let’s just fine-tune it” without a framework behind that decision is often where the failure starts.
4. Compliance requirements are now a real constraint, not an afterthought. In regulated environments under frameworks like GDPR, HIPAA, or sector-specific financial regulations, RAG’s ability to provide source-traceable answers is becoming less of a nice-to-have and more of an operational requirement. Fine-tuned models require additional evaluation evidence and periodic bias and hallucination checks to satisfy compliance reviewers in these environments.
5. The “more customized” feeling of fine-tuning is often a trap. Many teams gravitate toward fine-tuning because it sounds more sophisticated and more tailored to their business. In practice, this instinct frequently leads to overbuilding a complex, expensive solution for a problem that a properly built RAG system would have solved faster and at a fraction of the cost.
How This Connects to Broader AI Agent Strategy
Fine-tuning vs RAG does not exist in isolation. It is one architectural decision inside a much larger system, especially as more businesses move toward AI agents that combine reasoning, tool use, and memory across multiple steps rather than a single question-and-answer exchange.
In agentic systems, RAG typically handles the agent’s access to current, factual knowledge during a task, while fine-tuning — when used — shapes how the agent reasons through multi-step workflows and formats its outputs for downstream tools. Our complete guide to agentic AI in 2026 covers how this knowledge-versus-behavior split plays out across full agent architectures, not just single-turn chat systems.
If you are building or evaluating multi-agent automation for your business, our breakdown of multi-agent systems for enterprise automation and our comparison of the top AI agent frameworks both build directly on the fine-tuning vs RAG decision covered here.
Quick Action Steps: Make the Fine-Tuning vs RAG Decision This Week
Step 1: List how often the knowledge your AI system needs actually changes — daily, weekly, monthly, or rarely. This single answer eliminates most of the guesswork immediately.
Step 2: Identify whether your real problem is a knowledge gap or a behavior gap. If the model knows the right facts but responds inconsistently, that is a behavior problem fine-tuning is built for. If it confidently states wrong or outdated facts, that is a knowledge problem RAG is built for.
Step 3: Honestly assess your team’s ML engineering capacity. If you do not have dedicated resources for training pipelines and evaluation infrastructure, default to RAG.
Step 4: If both knowledge currency and behavioral consistency genuinely matter for your use case, plan for the hybrid pattern from the start rather than retrofitting it later.
Step 5: Build a small pilot before committing to a full architecture. Test it against real queries from real users before scaling either approach across your organization.
For a foundational look at how AI is reshaping business and trading operations more broadly, read our complete guide on AI in trading and business for 2026.
Frequently Asked Questions
What is the main difference between fine-tuning and RAG?
Fine-tuning changes the internal weights of a model through additional training, altering how it behaves and reasons. RAG leaves the model unchanged and instead retrieves relevant external information at the moment of a query, feeding it into the model’s prompt. Fine-tuning changes behavior; RAG changes available knowledge.
Which is cheaper, fine-tuning or RAG?
For most business use cases, RAG is cheaper and faster to reach a production-quality system. Fine-tuning only becomes more cost-effective on total cost of ownership when query volume is extremely high and the fine-tuned model’s reduced per-query cost offsets the significant upfront training investment over time.
Can I use both fine-tuning and RAG together?
Yes, and this hybrid approach has become a standard pattern in 2026 for production systems that need both consistent behavior and current knowledge. A common architecture fine-tunes a smaller model for tone, format, and domain vocabulary, then places that model behind a RAG pipeline for real-time factual grounding.
Does RAG require machine learning expertise to set up?
RAG generally requires less specialized machine learning expertise than fine-tuning, since it relies more on data engineering — document chunking, embedding, and vector database management — than on model training. Fine-tuning requires dedicated ML engineering capacity for training runs and proper model evaluation.
Is fine-tuning becoming obsolete because of RAG?
No. Fine-tuning remains the better choice for specific situations involving stable domain language, strict output format requirements, or extremely high query volumes on narrow tasks. The two approaches solve different problems and are increasingly used together rather than one replacing the other.
How much data do I need to fine-tune a model?
Most fine-tuning projects require hundreds to thousands of high-quality, labeled training examples, along with sufficient compute resources for the training process and an evaluation pipeline to confirm the fine-tuned model genuinely outperforms the base model on your specific task.
Why do so many enterprise AI pilots fail to scale?
A significant factor cited across industry reporting is architecture decisions made too early in a project, before teams fully understand their knowledge volatility, compliance requirements, and team capabilities. Choosing between fine-tuning and RAG without a clear framework is one of the most common early mistakes that prevents pilots from reaching full production deployment.
Disclaimer: This article is for educational and informational purposes only and does not constitute technical, engineering, or business consulting advice. AI architecture decisions should be evaluated based on your organization’s specific technical requirements, compliance obligations, and available resources. The Data Pips Team makes no guarantees regarding outcomes from applying the strategies described in this article. Consult a qualified AI or machine learning engineering professional before making significant architecture decisions for production systems.



