Key Takeaways
- An LLM (Large Language Model) is the technology behind tools like ChatGPT — an AI trained on enormous amounts of text to understand and generate human-like language.
- At its core, an LLM does one thing: it predicts the next word (or token) over and over, based on patterns it learned from massive amounts of text.
- “Large” refers to two things: the enormous amount of text it was trained on, and the billions of internal settings (parameters) it uses.
- An LLM does not “understand” or “know” things the way humans do — it recognizes and reproduces patterns in language, which is powerful but has real limits.
- Understanding what an LLM is explains why AI is so capable at language tasks, yet also why it hallucinates, has knowledge cutoffs, and sometimes gets simple things wrong.
You use it, you have heard the term everywhere, and you have probably nodded along in conversations about it — but if someone asked you to explain what an LLM actually is, could you? Most people cannot, and that is not their fault. The technology behind ChatGPT and every modern AI tool is wrapped in intimidating jargon that hides a surprisingly understandable core idea.
LLM stands for Large Language Model, and it is the engine powering the AI revolution you are living through. Understanding what it is — really understanding it, not just memorizing the words — changes how you see every AI tool you touch. It explains why AI is so astonishingly good at some things and so frustratingly bad at others. It demystifies the “magic” into something you can actually reason about.
This guide explains what an LLM is in plain language, for someone who is not a programmer or a data scientist. The Data Pips Team will show you what it is, how it actually works at its core, what “large” really means, and why understanding this makes you a smarter user of AI. No assumptions about technical background. By the end, you will understand the foundation of modern AI. Let us get into it.
What Is an LLM — In Plain English?
Let us define it simply.
An LLM (Large Language Model) is a type of AI that has been trained on an enormous amount of text so that it can understand and generate human-like language.
Let us break down that name, because it explains a lot:
- Large — it is trained on a vast amount of text (much of the public internet, books, articles), and it has billions of internal settings. It is “large” in both data and size.
- Language — its specialty is language: reading it, understanding patterns in it, and producing it. Text in, text out.
- Model — in AI, a “model” is a system that has learned patterns from data and can then make predictions or generate output based on those patterns.
So an LLM is a large model that specializes in language. According to IBM, large language models are AI systems trained on massive datasets of text that can recognize, understand, and generate human language. They are the technology behind chatbots, AI writing assistants, AI coding tools, and most of the generative AI applications you have encountered.
Here is the crucial thing to understand from the start: despite producing remarkably human-like language, an LLM is not thinking the way a human does. It is doing something much more mechanical than it appears — and understanding that mechanism is the key to understanding everything else about AI.
— Data Pips Team
How an LLM Actually Works: The One Core Idea
Strip away all the complexity, and an LLM does one fundamental thing, over and over:
It predicts the next word (or token) based on everything that came before.
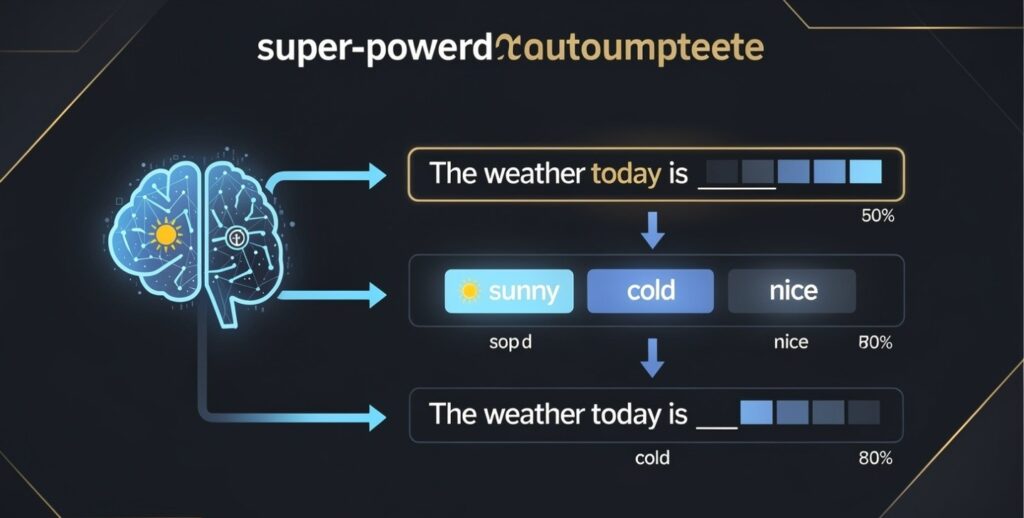
That is genuinely the core of it. When you give an LLM some text and ask it to continue or respond, it works through the text and predicts what should come next — one piece at a time. It predicts the most likely next word, adds it, then predicts the next word after that, then the next, building up its response piece by piece. (These pieces are technically called tokens — our guide on AI tokens and context windows explains exactly what those are.)
Think of it like an extraordinarily sophisticated version of the autocomplete on your phone. When you type “I’m running late, I’ll be there in five…” your phone suggests “minutes.” It learned that pattern from seeing the phrase countless times. An LLM does this same basic thing — predicting what comes next — but at an almost unimaginably more powerful scale, trained on a huge portion of all the text humanity has written.
This is why an LLM can write essays, answer questions, and hold conversations: because predicting the next word, when done well enough across enough context, produces coherent, relevant, intelligent-seeming language. The LLM learned the patterns of how language works — how questions are answered, how arguments are structured, how stories flow — and it reproduces those patterns by predicting, word by word, what fits best.
The technical breakthrough that made modern LLMs possible is an architecture called the transformer, which lets the model pay attention to the relationships between all the words in a passage at once. You do not need the technical details — just know that this innovation is what allowed next-word prediction to become powerful enough to produce the fluent AI we have today.
What Does “Large” Actually Mean?
The “large” in Large Language Model is not just marketing — it refers to two specific things that make these models so capable.
1. A Massive Amount of Training Data
An LLM is trained on an enormous quantity of text — a huge portion of the public internet, vast collections of books, articles, conversations, code, and more. We are talking about an amount of text no human could read in thousands of lifetimes. This massive exposure is how the model learns the patterns of language, facts, reasoning styles, and writing structures. The more high-quality text it learns from, the better its patterns become.
2. Billions of Parameters
An LLM has a huge number of internal settings called “parameters” — often billions of them. You can think of parameters as the tiny adjustable dials that store everything the model learned during training. During training, these billions of dials get tuned, little by little, so that the model gets better and better at predicting language. The more parameters (generally), the more capacity the model has to capture complex patterns. This is why model sizes are often described by their parameter count.
So “large” means: trained on a massive amount of text, using a massive number of internal parameters. Both of these are what give LLMs their remarkable abilities. They are also why training these models requires enormous computing power and resources — building a large LLM from scratch is extraordinarily expensive, which is why only well-resourced organizations create the foundational models that everyone else builds upon.
The Training Process: How an LLM Learns
Understanding roughly how an LLM is trained helps demystify it further. There are two main phases.
Phase 1: Pre-Training (Learning Language Itself)
In the first phase, the model is fed that massive amount of text and given a simple task: predict the next word in countless examples. It reads a passage, tries to predict the next word, checks if it was right, and adjusts its billions of parameters slightly to do better next time. Repeated billions upon billions of times, this process gradually tunes the model into an extraordinary pattern-recognizer that has absorbed the structure of language, a vast amount of factual information, and many styles of reasoning. This is where the bulk of the model’s raw capability comes from.
Phase 2: Fine-Tuning and Alignment (Making It Helpful)
After pre-training, the model can predict text well but is not yet a helpful, safe assistant. So it goes through additional training to shape its behavior — teaching it to follow instructions, be helpful, avoid harmful outputs, and respond in useful ways. This often involves human feedback, where people rate the model’s responses to guide it toward better behavior. This phase turns a raw text-predictor into the polished assistant you actually interact with. The concept of fine-tuning extends to customizing models for specific tasks too — our guide on fine-tuning vs RAG explores this in more depth.
After both phases, the model’s knowledge is essentially “frozen” at the point training ended — which is why LLMs have a knowledge cutoff and do not know about events after their training. This frozen knowledge is also part of why techniques like RAG exist, to give the model access to current information.
Understanding It: Why the LLM Is Both Brilliant and Flawed
Once you understand that an LLM is a massive next-word predictor trained on huge amounts of text, its strange mix of brilliance and failure suddenly makes perfect sense.
Why it is brilliant at language: It learned the patterns of how good language works from more text than any human could ever read. So it writes fluently, answers in well-structured ways, adapts to different styles, and handles an enormous range of language tasks — because predicting the next word well, at scale, produces exactly this kind of capability.
Why it hallucinates: Since its job is to produce plausible-sounding text rather than verified truth, when it lacks real information it fills the gap with plausible invention. Our guide on why AI hallucinations happen explores this directly — and it all traces back to the next-word-prediction nature of LLMs.
Why it has a knowledge cutoff: Its knowledge was frozen when training ended, so it does not know recent events.
Why it sometimes fails at simple things: It does not truly “reason” or “calculate” like a logic machine — it predicts language patterns, so tasks requiring precise logic or exact computation can trip it up even as it handles complex language beautifully.
Lesson: Every strength and every weakness of an LLM flows from the same source — it is a powerful language-pattern predictor, not a thinking, knowing, calculating mind. Understanding this one fact explains the whole picture.
What an LLM Is NOT (Common Misconceptions)
Just as important as understanding what an LLM is, is understanding what it is not. Clearing up these misconceptions makes you a far wiser user.
It Is Not a Search Engine or Database
An LLM does not “look up” facts in a stored database. It generates text based on learned patterns. This is why it can be confidently wrong — it is not retrieving a verified record, it is predicting plausible language. When an AI tool does seem to look things up, it is usually because it has been connected to a search tool or a retrieval system like RAG, separate from the core LLM.
It Does Not “Understand” Like a Human
While an LLM produces language that seems to reflect understanding, it does not understand meaning the way you do. It recognizes and reproduces patterns extraordinarily well, which can look like understanding, but there is no human-like comprehension or consciousness behind it. This is a subtle but important distinction — the appearance of understanding is produced by pattern mastery, not by genuine human-style thought.
It Is Not Always Right (Or Aware When It Is Wrong)
Because it produces plausible text rather than verified truth, an LLM can be confidently incorrect and has no reliable internal sense of when it is wrong. This is why you should never blindly trust an LLM for important factual matters without verification — its confidence is a feature of how it writes, not a measure of accuracy.
It Is Not Conscious or Sentient
Despite producing human-like language and sometimes seeming to express thoughts or feelings, an LLM is not conscious, does not have genuine emotions, and is not self-aware in any human sense. It is a sophisticated pattern-prediction system. The human-like quality of its output can create a powerful illusion of a mind, but it remains a tool — an impressive one, but a tool nonetheless.
— Data Pips Team
Why Understanding LLMs Matters for You
This is not just academic knowledge — understanding what an LLM is makes you genuinely better at using AI.
You Use AI for the Right Tasks
Knowing that LLMs excel at language and pattern tasks but struggle with precise logic, exact calculation, and verified facts helps you use them where they shine and verify them where they are weak. You stop being surprised by their failures and start working with their actual capabilities.
You Spot and Guard Against Their Weaknesses
Understanding that LLMs predict plausible text rather than retrieve verified facts means you naturally verify important claims, stay alert to hallucinations, and remember the knowledge cutoff. You become a critical, capable user instead of a blindly trusting one.
You Prompt More Effectively
Knowing how LLMs work — that they respond to patterns and context — helps you write better prompts. You provide clear context, give examples, and structure your requests in ways that work with how the model actually processes language, getting dramatically better results.
You Gain a Genuinely Valuable Skill
As LLMs become embedded in more and more work, understanding how they actually function — not just how to push buttons, but how the technology works — is a real and growing advantage. The people who understand AI at this level use it far more effectively than those who treat it as inscrutable magic. This kind of foundational AI literacy is exactly the sort of skill that compounds into real opportunity as AI continues reshaping how work gets done.
What Nobody Tells Beginners About LLMs
1. The “Intelligence” Is an Emergent Surprise
Here is something genuinely fascinating: nobody explicitly programmed an LLM to answer questions, write code, or reason through problems. These abilities emerged on their own from the simple task of next-word prediction at massive scale. The model learned these capabilities as a side effect of getting very good at predicting language. This emergent quality is part of why LLMs are both powerful and somewhat unpredictable — even their creators do not fully understand everything happening inside them.
2. Bigger Is Not Always Better
While “large” is in the name, the biggest model is not always the best choice. Smaller, more efficient models can be cheaper, faster, and perfectly capable for many tasks — sometimes even better when specialized for a specific purpose. The trend is increasingly toward matching the right-sized model to the task rather than always reaching for the biggest one. Bigger means more capacity, but also more cost and slower responses, so the best model depends on what you actually need.
3. The Same Model Powers Many Different Tools
Many different AI products are built on top of the same underlying LLMs. A foundational model gets created by a well-resourced organization, and then countless other tools and companies build their applications on top of it. This is why so many AI tools feel similar — they often share the same underlying engine, customized in different ways. Understanding this helps you see the AI landscape more clearly: the foundational models are the engines, and the tools you use are the cars built around them.
4. Quality of Training Data Shapes Everything
An LLM is profoundly shaped by the text it learned from. If the training data contained biases, errors, or gaps, those tend to show up in the model’s behavior. This is why LLMs can reflect biases present in their training data and why the quality and composition of training data is such an important topic. The model is a mirror, in some sense, of the vast text it absorbed — including both the wisdom and the flaws in that text.
5. You Do Not Need to Be Technical to Benefit Deeply
Understanding LLMs at the conceptual level — the level in this article — is enough to dramatically improve how you use AI, without any programming or math. The core ideas (next-word prediction, training on massive text, pattern recognition rather than true understanding) are graspable by anyone. You do not need to build an LLM to benefit from understanding one, just as you do not need to be a mechanic to be a skilled driver. Conceptual understanding alone is a real and accessible edge.
Quick Action Steps
Now It’s Your Move
- Remember the one core idea. An LLM predicts the next word, over and over, based on patterns learned from massive text. It is a super-powered autocomplete. This single idea explains almost everything.
- Know what “large” means. Trained on a massive amount of text, using billions of internal parameters. Both data and size make LLMs capable.
- Understand it predicts, it does not look up. An LLM is not a database or search engine. It generates plausible text, which is why it can be confidently wrong.
- Use LLMs for their strengths. They excel at language and pattern tasks. Verify them on precise facts, exact calculations, and logic where they are weaker.
- Remember the knowledge cutoff. An LLM’s knowledge is frozen at training time. For current information, you need tools that connect it to search or retrieval like RAG.
- Prompt with how it works in mind. Provide clear context and examples, since the model responds to patterns. Better input produces dramatically better output.
- Stay a critical user. The human-like output creates an illusion of a thinking mind. Remember it is a powerful tool, not a conscious being, and verify what matters.
Frequently Asked Questions
An LLM (Large Language Model) is a type of AI trained on an enormous amount of text so that it can understand and generate human-like language. It is the technology behind tools like ChatGPT and most modern AI applications. Breaking down the name: “Large” means it was trained on a vast amount of text and has billions of internal settings; “Language” means its specialty is reading and producing language; and “Model” means it is a system that learned patterns from data. At its core, an LLM works by predicting the next word over and over, based on patterns it learned, building up responses one piece at a time.
At its core, an LLM does one fundamental thing: it predicts the next word (or token) based on everything that came before, then repeats this over and over to build a response. Think of it as an extraordinarily sophisticated version of your phone’s autocomplete, but trained on a huge portion of all the text humanity has written. It learned the patterns of how language works — how questions get answered, how arguments are structured — and reproduces those patterns by predicting, piece by piece, what fits best. This next-word prediction, done well enough at massive scale, produces coherent, intelligent-seeming language, which is why LLMs can write, answer questions, and converse.
The “large” refers to two specific things. First, the massive amount of training data: an LLM is trained on an enormous quantity of text — much of the public internet, vast collections of books and articles — far more than any human could read in thousands of lifetimes. Second, the billions of parameters: an LLM has a huge number of internal settings (often billions) that store everything it learned during training, like adjustable dials that get tuned to make it better at predicting language. So “large” means trained on a massive amount of text using a massive number of internal parameters, and both are what give LLMs their remarkable capabilities.
Not in the way humans understand. While an LLM produces language that seems to reflect genuine understanding, it does not comprehend meaning the way a person does. It recognizes and reproduces patterns in language extraordinarily well, which can look like understanding, but there is no human-like comprehension or consciousness behind it. The appearance of understanding is produced by mastery of language patterns, not by actual human-style thought. This is an important distinction: an LLM is a sophisticated pattern-prediction system, not a thinking, knowing, conscious mind, even though its fluent output can create a powerful illusion that it understands.
LLMs make mistakes because of their fundamental nature: they predict plausible-sounding text rather than retrieve verified facts. When an LLM lacks real information, it fills the gap with plausible invention (hallucination), because producing fluent text is what it was built to do. They also have a knowledge cutoff (their knowledge is frozen at training time, so they do not know recent events), and they do not truly reason or calculate like a logic machine — they predict language patterns, so tasks requiring precise logic or exact computation can trip them up. Every weakness flows from the same source: an LLM is a powerful language-pattern predictor, not a thinking, knowing, calculating mind.
Not exactly — ChatGPT is an AI product built on top of an LLM, but the two are not identical. The LLM is the underlying engine (the large language model that predicts text), while ChatGPT is the complete application you interact with, which includes the LLM plus additional components like a chat interface, possible connections to search or tools, and behavior shaping. In fact, many different AI products are built on top of the same underlying LLMs. A useful way to think about it: foundational LLMs are the engines, and tools like ChatGPT are the cars built around them. So an LLM powers ChatGPT, but ChatGPT is more than just the raw LLM.
No. Understanding LLMs at the conceptual level is enough to dramatically improve how you use AI, and it requires no programming or math. The core ideas — that an LLM predicts the next word, that it was trained on massive amounts of text, and that it recognizes patterns rather than truly understanding — are graspable by anyone. You do not need to build an LLM to benefit from understanding one, just as you do not need to be a mechanic to be a skilled driver. This conceptual understanding helps you use AI for the right tasks, guard against its weaknesses, prompt more effectively, and become a far more capable AI user, all without any technical background.

Now It’s Your Move
The term you have heard a hundred times — LLM — now has real meaning for you. A Large Language Model is an AI trained on an enormous amount of text that works by doing one thing remarkably well: predicting the next word, over and over, based on the patterns it learned. It is, at its heart, a super-powered autocomplete trained on a huge portion of everything humanity has written. That simple core, scaled up massively, produces the fluent, capable AI that is reshaping the world.
And here is the insight that changes everything: once you understand that an LLM is a language-pattern predictor rather than a thinking, knowing, calculating mind, all of its behavior makes sense. Its brilliance at language, its tendency to hallucinate, its knowledge cutoff, its occasional failures at simple logic — every strength and every weakness flows from the same single truth. AI stops being inexplicable magic and becomes a tool you can actually reason about and use wisely.
This understanding is not reserved for engineers. The conceptual grasp you now have — next-word prediction, training on massive text, pattern recognition rather than true understanding — is enough to make you a dramatically better, more critical, more effective user of every AI tool you touch. You do not need to build an LLM to benefit from understanding one, just as you do not need to be a mechanic to be a skilled driver.
Remember the core idea. Know what “large” means. Understand that it predicts rather than looks up. Use LLMs for their strengths and verify their weaknesses. Remember the knowledge cutoff. And always keep in mind that the human-like output is a powerful illusion produced by pattern mastery, not a sign of a conscious mind.
You now understand the foundation of modern AI — the engine behind the entire revolution you are living through. Most people use these tools every day without ever understanding what powers them. You are no longer one of them.
For your next steps, deepen your understanding with our guides on AI tokens and context windows (the pieces an LLM predicts), why AI hallucinations happen (a direct consequence of how LLMs work), and what RAG is (how LLMs get connected to real, current information).


